In my first class in computer science, I was taught that an algorithm is simply a way of expressing formal rules given to a computer. Computers like rules. They follow them. Turns out that bureaucracy and legal systems like rules too. The big difference is that, in the world of computing, we call those who are trying to find ways to circumvent the rules “hackers” but in the world of government, this is simply the mundane work of politicking and lawyering.
When Dan Bouk (and I, as an earnest student of his) embarked on a journey to understand the history of the 1920 census, we both expected to encounter all sorts of politicking and lawyering. As scholars fascinated by the census, we’d heard the basics of the story: Congress failed to reapportion itself after receiving data from the Census Bureau because of racist and xenophobic attitudes mixed with political self-interest. In other words, politics.
As we dove into this history, the first thing we realized was that one justification for non-apportionment centered on a fight about math. Politicians seemed to be arguing with each other over which algorithm was the right algorithm with which to apportion the House. In the end, they basically said that apportionment should wait until mathematicians could figure out what the “right” algorithm was. (Ha!) The House didn’t manage to pass an apportionment bill until 1929 when political negotiations had made this possible. (This story anchors our essay on “Democracy’s Data Infrastructure.”)
Dan kept going, starting what seemed like a simple question: what makes Congress need an algorithm in the first place? I bet you can’t guess what the answer is! Wait for it… wait for it… Politics! Yes, that’s right, Congress wanted to cement an algorithm into its processes in a feint attempt to de-politicize the reapportionment process. With a century of extra experience with algorithms, this is patently hysterical. Algorithms as a tool to de-politicize something!?!? Hahahah. But, that’s where they had gotten to. And now the real question was: why?

In Dan’s newest piece – “House Arrest: How an Automated Algorithm Constrained Congress for a Century” – Dan peels back the layers of history with beautiful storytelling and skilled analysis to reveal why our contemporary debates about algorithmic systems aren’t so very new. Turns out that there were a variety of political actors deeply invested in ensuring that the People’s House stopped growing. Some of their logics were rooted in ideas about efficiency, but some were rooted in much older ideas of power and control. (Don’t forget that the electoral college is tethered to the size of the House too!) I like to imagine power-players sitting around playing with their hands and saying mwah-ha-ha-ha as they strategize over constraining the growth of the size of the House. They wanted to do this long before 1920, but it didn’t get locked in then because they couldn’t agree, which is why they fought over the algorithm. By 1929, everyone was fed up and just wanted Congress to properly apportion and so they passed a law, a law that did two things: it stabilized the size of the House at 435 and it automated the apportionment process. Those two things – the size of the House and the algorithm – were totally entangled. After all, an automated apportionment couldn’t happen without the key variables being defined.
Of course, that’s not the whole story. That 1929 bill was just a law. Up until then, Congress had passed a new law every decade to determine how apportionment would work for that decade. But when the 1940 census came around, they were focused on other things. And then, in effect, Congress forgot. They forgot that they have the power to determine the size of the House. They forgot that they have control over that one critical variable. The algorithm became infrastructure and the variable was summarily ignored.
Every decade, when the Census data are delivered, there are people who speak out about the need to increase the size of the House. After all, George Washington only spoke once during the Constitutional Convention. He spoke up to say that we couldn’t possibly have Congresspeople represent 40,000 people because then they wouldn’t trust government! The constitutional writers listened to him and set the minimum at 30,000; today, our representatives each represent more than 720,000 of us.
After the 1790 census, there were 105 representatives in Congress. Every decade, that would increase. Even though it wasn’t exact, there was an implicit algorithm in that size increase. In short, increase the size of the House so that no sitting member would lose his seat. After all, Congress had to pass that bill and this was the best way to get everyone to vote on it. The House didn’t increase at the same ratio as the size of the population, but it did increase every decade until 1910. And then it stopped (with extra seats given to new states before being brought back to the zero-sum game at the next census).
One of the recommendations of the Commission on the Practice of Democratic Citizenship (for which I was a commissioner) was to increase the size of the House. When we were discussing this as a commission, everyone spoke of how radical this proposition was, how completely impossible it would be politically. This wasn’t one of my proposals – I wasn’t even on that subcommittee – so I listened with rapt curiosity. Why was it so radical? Dan taught me the answer to that. The key to political power is to turn politicking into infrastructure. After all, those who try to break a technical system, to work around an algorithm, they’re called hackers. And hackers are radical.
Want more like this?
- Read “House Arrest: How an Automated Algorithm Constrained Congress for a Century” by Dan Bouk. There’s drama! And intrigue! And algorithms!
- Read “Democracy’s Data Infrastructure” by Dan Bouk and me. It might shape your view about public fights over math.
- Sign up for my newsletter. More will be coming, I promise!


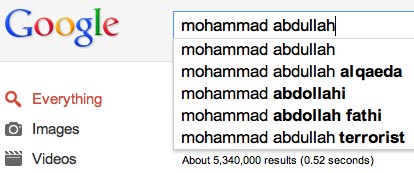 You’re a 16-year-old Muslim kid in America. Say your name is Mohammad Abdullah. Your schoolmates are convinced that you’re a terrorist. They keep typing in Google queries likes “is Mohammad Abdullah a terrorist?” and “Mohammad Abdullah al Qaeda.” Google’s search engine learns. All of a sudden, auto-complete starts suggesting terms like “Al Qaeda” as the next term in relation to your name. You know that colleges are looking up your name and you’re afraid of the impression that they might get based on that auto-complete. You are already getting hostile comments in your hometown, a decidedly anti-Muslim environment. You know that you have nothing to do with Al Qaeda, but Google gives the impression that you do. And people are drawing that conclusion. You write to Google but nothing comes of it. What do you do?
You’re a 16-year-old Muslim kid in America. Say your name is Mohammad Abdullah. Your schoolmates are convinced that you’re a terrorist. They keep typing in Google queries likes “is Mohammad Abdullah a terrorist?” and “Mohammad Abdullah al Qaeda.” Google’s search engine learns. All of a sudden, auto-complete starts suggesting terms like “Al Qaeda” as the next term in relation to your name. You know that colleges are looking up your name and you’re afraid of the impression that they might get based on that auto-complete. You are already getting hostile comments in your hometown, a decidedly anti-Muslim environment. You know that you have nothing to do with Al Qaeda, but Google gives the impression that you do. And people are drawing that conclusion. You write to Google but nothing comes of it. What do you do?