
What follows is the crib from my keynote at the 2017 Strata Data Conference in New York City. Full video can be found here.
In 1998, two graduate students at Stanford decided to try to “fix” the problems with major search engines. Sergey Brin and Larry Page wrote a paper describing how their PageRank algorithm could eliminate the plethora of “junk results.” Their idea, which we all now know as the foundation of Google, was critical. But it didn’t stop people from trying to mess with their system. In fact, the rise of Google only increased the sophistication of those invested in search engine optimization.

Fast forward to 2003, when the sitting Pennsylvania senator Rick Santorum publicly compared homosexuality to bestiality and pedophilia. Needless to say, the LGBT community was outraged. Journalist Dan Savage called on his readers to find a way to “memorialize the scandal.” One of his fans created a website to associate Santorum’s name with anal sex. To the senator’s horror, countless members of the public jumped in to link to that website in an effort to influence search engines. This form of crowdsourced SEO is commonly referred to as “Google bombing,” and it’s a form of media manipulation intended to mess with data and the information landscape.

Media manipulation is not new. As many adversarial actors know, the boundaries between propaganda and social media marketing are often fuzzy.Furthermore, any company that uses public signals to inform aspects of its product — from Likes to Comments to Reviews — knows full well that any system you create will be gamed for fun, profit, politics, ideology, and power.Even Congress is now grappling with that reality. But I’m not here to tell you what has always been happening or even what is currently happening — I’m here to help you understand what’s about to happen.
At this moment, AI is at the center of every business conversation. Companies, governments, and researchers are obsessed with data. Not surprisingly, so are adversarial actors. We are currently seeing an evolution in how data is being manipulated. If we believe that data can and should be used to inform people and fuel technology, we need to start building the infrastructure necessary to limit the corruption and abuse of that data — and grapple with how biased and problematic data might work its way into technology and, through that, into the foundations of our society.
In short, I think we need to reconsider what security looks like in a data-driven world.

Part 1: Gaming the System
Like search engines, social media introduced a whole new target for manipulation. This attracted all sorts of people, from social media marketers to state actors. Messing with Twitter’s trending topics or Facebook’s news feed became a hobby for many. For $5, anyone could easily buy followers, likes, and comments on almost every major site. The economic and political incentives are obvious, but alongside these powerful actors, there are also a whole host of people with less-than-obvious intentions coordinating attacks on these systems.
For example, when a distributed network of people decided to help propel Rick Astley to the top of the charts 20 years after his song “Never Gonna Give You Up” first came out, they weren’t trying to help him make a profit (although they did). Like other memes created through networks on sites like 4chan, rickrolling was for kicks. Butthrough this practice, lots of people learned how to make content “go viral” or otherwise mess with systems. In other words, they learned to hack the attention economy. And, in doing so, they’ve developed strategic practices of manipulation that can and do have serious consequences.
A story like “#Pizzagate” doesn’t happen accidentally — it was produced by a wide network of folks looking to toy with the information ecosystem. They created a cross-platform network of fake accounts known as“sock puppets” which they use to subtly influence journalists and other powerful actors to pay attention to strategically produced questions, blog posts, and YouTube videos. The goal with a story like that isn’t to convince journalists that it’s true, but to get them to foolishly use their amplification channels to negate it. This produces a “Boomerang effect,” whereby those who don’t trust the media believe that there must be merit to the conspiracy, prompting some to “self-investigate.”
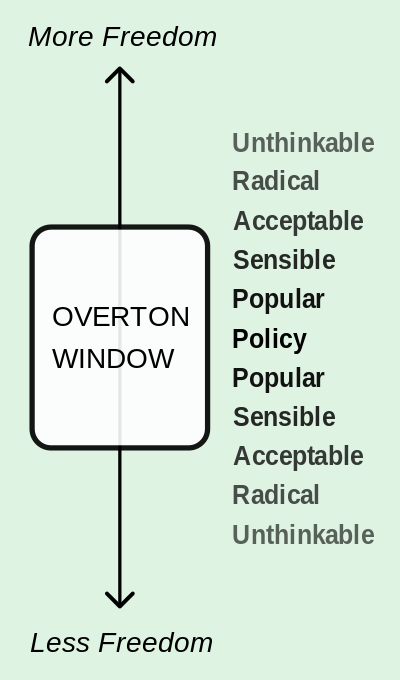
Then there’s the universe of content designed to “open the Overton window” — or increase the range of topics that are acceptable to discuss in public. Journalists are tricked into spreading problematic frames. Moreover,recommendation engines can be used to encourage those who are open to problematic frames to go deeper. Researcher Joan Donovan studies white supremacy; after work, she can’t open Amazon, Netflix, or YouTube without being recommended to consume neo-Nazi music, videos, and branded objects. Radical trolls also know how to leverage this infrastructure to cause trouble. Without tripping any of Twitter’s protective mechanisms, the well-known troll weev managed to use the company’s ad infrastructure to amplify white supremacist ideas to those focused on social justice, causing outrage and anger.
By and large, these games have been fairly manual attacks of algorithmic systems, but as we all know, that’s been changing. And it’s about to change again.
Part 2: Vulnerable Training Sets
Training a machine learning system requires data. Lots of it. While there are some standard corpuses, computer science researchers, startups, and big companies are increasingly hungry for new — and different — data.

The first problem is that all data is biased, most notably and recognizably by reflecting the biases of humans and of society in general. Take, for example, the popular ImageNet dataset. Because humans categorize by shape faster than they categorize by color, you end up with some weird artifacts in that data.
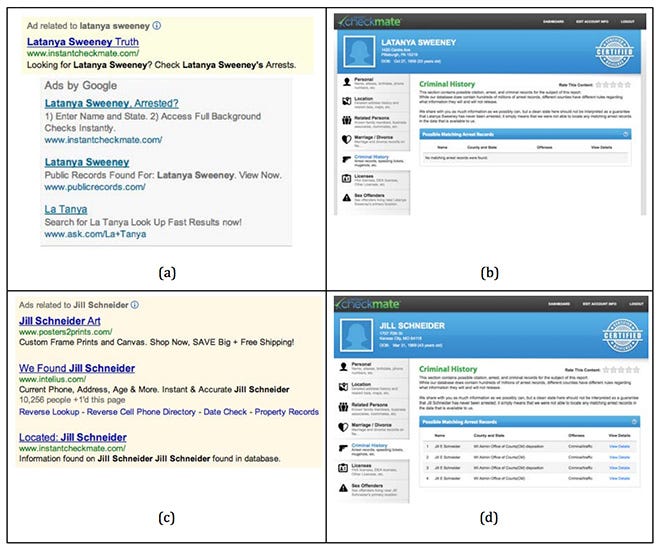
Things get even messier when you’re dealing with social prejudices. WhenLatanya Sweeney searched for her name on Google, she was surprised to be given ads inviting her to find out if she had a criminal record. As a curious computer scientist, she decided to run a range of common black and white names through the system to see which ads popped up. Unsurprisingly, onlyblack names produced ads for criminal justice products. This isn’t because Google knowingly treated the names differently, but because searchers were more likely to click on criminal justice ads when searching for black names.Google learned American racism and amplified it back at all of its users.
Addressing implicit and explicit cultural biases in data is going to be a huge challenge for everyone who is trying to build a system dependent on data classified by or about humans.
But there’s also a new challenge emerging. The same decentralized networks of people — and state actors — who have been messing with social media and search engines are increasingly eyeing the data that various companies use to train and improve their systems.
Consider, for example, the role of reddit and Twitter data as training data. Computer scientists have long pulled from the very generous APIs of these companies to train all sorts of models, trying to understand natural language, develop metadata around links, and track social patterns. They’ve trained models to detect depression, rank news, and engage in conversation. Ignoring the fact that this data is not representative in the first place, most engineers who use these APIs believe that it’s possible to clean the data and remove all problematic content. I can promise you it’s not.
No amount of excluding certain subreddits, removing of categories of tweets, or ignoring content with problematic words will prepare you for those who are hellbent on messing with you.
I’m watching countless actors experimenting with ways to mess with public data with an eye on major companies’ systems. They are trying to fly below the radar. If you don’t have a structure in place for strategically grappling with how those with an agenda might try to route around your best laid plans, you’re vulnerable. This isn’t about accidental or natural content. It’s not even about culturally biased data. This is about strategically gamified content injected into systems by people who are trying to guess what you’ll do.
If you want to grasp what that means, consider the experiment Nicolas Papernot and his colleagues published last year. In order to understand the vulnerabilities of computer vision algorithms, they decided to alter images of stop signs so that they still resembled a stop sign to a human viewer even as the underlying neural network interpreted them as a yield sign. Think about what this means for autonomous vehicles. Will this technology be widely adopted if the classifier can be manipulated so easily?
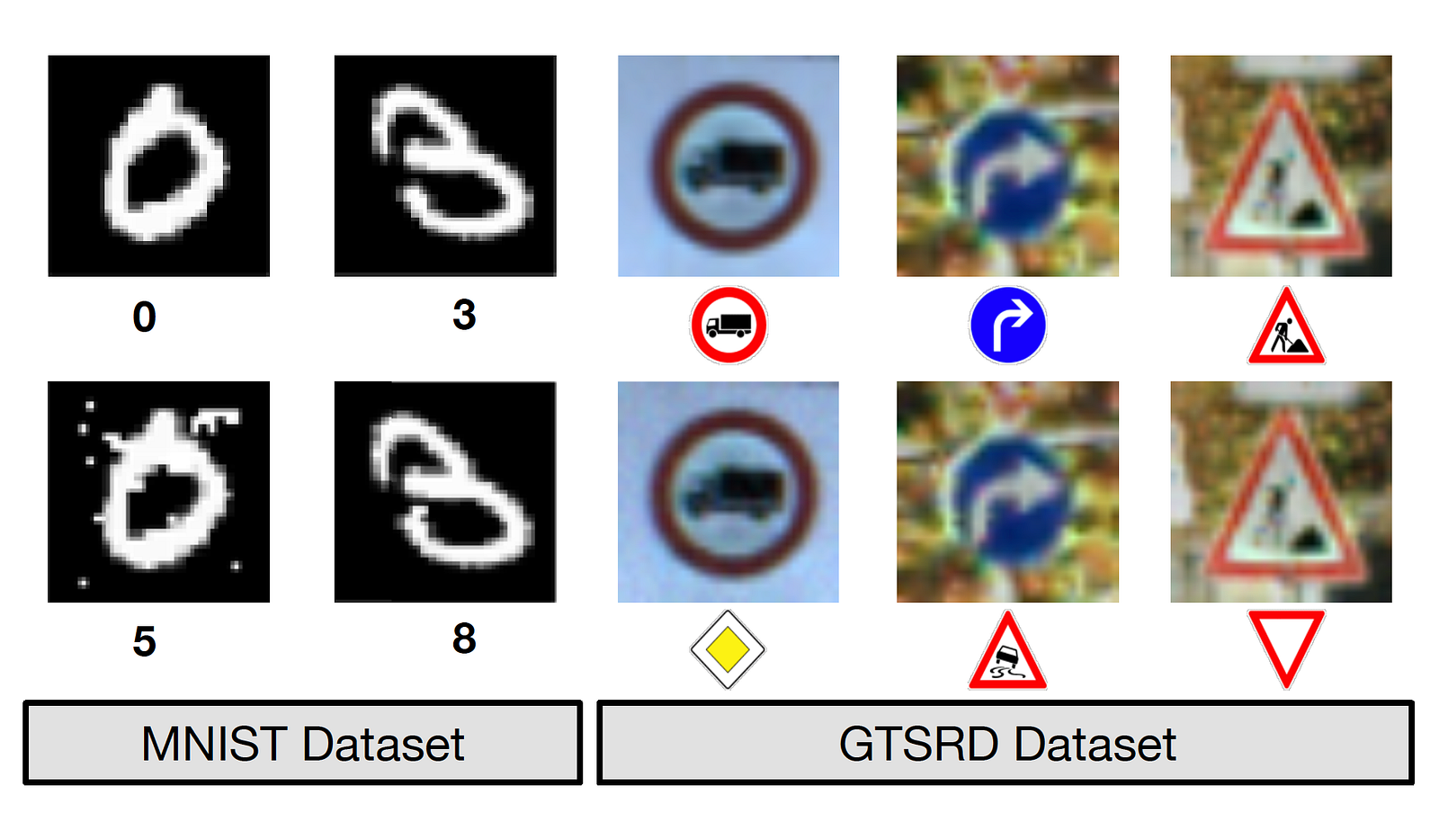
Right now, most successful data-injection attacks on machine learning modelsare happening in the world of research, but more and more, we are seeing people try to mess with mainstream systems. Just because they haven’t been particularly successful yet doesn’t mean that they aren’t learning and evolving their attempts.
Part 3: Building Technical Antibodies
Many companies spent decades not taking security vulnerabilities seriously, until breach after breach hit the news. Do we need to go through the same pain before we start building the tools to address this new vulnerability?
If you are building data-driven systems, you need to start thinking about how that data can be corrupted, by whom, and for what purpose.
In the tech industry, we have lost the culture of Test. Part of the blame rests on the shoulders of social media. Fifteen years ago, we got the bright idea to shift to a culture of the “perpetual beta.” We invited the public to be our quality assurance engineers. But internal QA wasn’t simply about finding bugs. It was about integrating adversarial thinking into the design and development process. And asking the public to find bugs in our systems doesn’t work well when some of those same people are trying to mess with our systems.Furthermore, there is currently no incentive — or path — for anyone to privately tell us where things go wrong. Only when journalists shame us by finding ways to trick our systems into advertising to neo-Nazis do we pay attention. Yet, far more maliciously intended actors are starting to play the long game in messing with our data. Why aren’t we trying to get ahead of this?
On the bright side, there’s an emergent world of researchers building adversarial thinking into the advanced development of machine learning systems.
Consider, for example, the research into generative adversarial networks (or GANs). For those unfamiliar with this line of work, the idea is that you have two unsupervised ML algorithms — one is trying to generate content for the other to evaluate. The first is trying to trick the second into accepting “wrong” information. This work is all about trying to find the boundaries of your model and the latent space of your data. We need to see a lot more R&D work like this — this is the research end of a culture of Test, with true adversarial thinking baked directly into the process of building models.

But these research efforts are not enough. We need to actively and intentionally build a culture of adversarial testing, auditing, and learning into our development practice. We need to build analytic approaches to assess the biases of any dataset we use. And we need to build tools to monitor how our systems evolve with as much effort as we build our models in the first place.My colleague Matt Goerzen argues that we also need to strategically invite white hat trolls to mess with our systems and help us understand our vulnerabilities.
The tech industry is no longer the passion play of a bunch of geeks trying to do cool shit in the world. It’s now the foundation of our democracy, economy, and information landscape.
We no longer have the luxury of only thinking about the world we want to build. We must also strategically think about how others want to manipulate our systems to do harm and cause chaos.
